6 非合作博弈的应用
在 Chapters 2-5 中,我们学习了有限策略非合作博弈。将策略的数量限制在有限范围内的原因是这类博弈有一些特殊的性质,例如二人零和博弈存在博弈值和最优策略,而有限非零和博弈存在混合策略纳什均衡。
在以上章节中讨论过的这些博弈论的基本概念也可以应用到更具一般性的博弈中。只要在一个博弈场景中能够定义参与人、他们的备选策略以及对应的收益,那么最佳响应和纳什均衡的概念就适用。逆向归纳法、子博弈完美性、完美贝叶斯均衡等概念和方法也能扩展至更具一般性的扩展式博弈中。对于不完全信息博弈,参与人类型的概念以及贝叶斯纳什均衡在无限策略的情况下也适用。
本章的目的是将通过不同的例子展示如何将博弈论的基本概念应用到各种包含冲突的情境中。当然,这些情境本身也是非常值得作为应用问题讨论的。
在 Section 6.1 中,我们将对 Chapter 2 和 Chapter 3 中的一些概念进行一般化。这一节只是为后续展示的例子提供基础分析框架,但是即使没有这一节的内容,大多数例子也是可以理解的。扩展式博弈和不完全信息博弈中的特有概念的一般化将在需要时给出。在 Sections 6.2-6.7 中我们将讨论以下内容:完全信息和不完全信息下的古诺竞争、伯特兰竞争、斯塔克尔伯格均衡、完全信息和不完全信息拍卖、客观概率混合策略、以及序贯议价。这些问题的更多变体可以在书中的第八节找到。
6.1 策略式博弈的通用分析框架
Chapter 2 中的矩阵博弈和 Chapter 3 中的双矩阵博弈都是以上框架中的特例,其中 S_i 是参与人 i 的所有混合策略的集合。这两章中关于纳什均衡和优势(劣势)策略的讨论也可以此设定下完成。
6.2 古诺产量竞争模型
6.2.1 完全信息下的简化版模型
这里我们从著名的古诺模型的简化版开始。假设两个企业生产同一种产品,并在产量上进行竞争。每个企业都决定为市场提供一定量的产品。市场价格通过总产量决定:总产量越高,则价格越低。每个企业的利润是其总收入(即价格与自身产量的积)与总成本之差。我们可以将这个情境描述为一个二人博弈,其中参与人是企业,策略是各自的产量,收益函数是各自的利润函数。为进一步简化分析,假设价格是总产量的线性函数,边际成本为正且恒定,固定成本为零。博弈的具体定义如下:
参与人集合为 N = \{1,2\}。
参与人 i 的策略集合为 S_i = [0,\infty),并用 q_i 代表具体的策略。
参与人 i 的收益函数为
\Pi_i(q_1, q_2) = q_i P(q_1, q_2) - c q_i .
这里 P(q_1, q_2) 是市场价格,其定义为
P(q_1, q_2) = \begin{cases} a - q_1 - q_2 & \text{if } \ q_1 + q_2 \leq a \\ 0 & \text{if } \ q_1 + q_2 > a \end{cases}
其中 a 为常数,c 为边际成本,且 a > c > 0。
此博弈的纳什均衡是互为最佳响应的策略组合 (q_1^C, q_2^C),即对所有的 q_1^C \geq 0, q_2^C \geq 0,
\Pi_1(q_1^C, q_2^C) \geq \Pi_1(q_1, q_2^C), \quad \Pi_1(q_1^C, q_2^C) \geq \Pi_1(q_1^C, q_2) .
此均衡也称为古诺均衡(Cournot equilibrium)。在具体计算时,可以首先计算最佳响应函数,也称为反应函数(reaction function)。参与人 1 的反应函数 \beta_1(q_2) 是通过在固定 q_2 的情况下解最大化问题
\max_{q_1 \geq 0} \Pi_1(q_1, q_2)
得到的。由于解对任意 q_2 都成立,所以是 q_2 的函数。如果 q_2 > a,则无论 q_1 取什么值,P(q_1, q_2) = 0,企业 1 的利润为 -cq_1。因此此时令收益最大的产量应为 q_1 = 0。如果 q_2 \leq a,则有
\Pi_1(q_1, q_2) = \begin{cases} q_1(a - q_1 - q_2) - c q_1 & \text{if } \ q_1 \leq a - q_2 \\ -c q_1 & \text{if } \ q_1 > a - q_2 \end{cases}
所以最大值点处于 0 \leq q_1 \leq a - q_2 的区间内,此时目标函数可以整理为
q_1(a - q_1 - q_2) - c q_1 = q_1(a - c - q_1 - q_2)
如果 q_2 > a - c 则二次函数的顶点的横坐标为负,最大值出现在 q_1 = 0 处。如果 q_2 \leq a - c,则最大值出现在顶点处,即 q_1 = (a - c - q_2) / 2。总结下来就是参与人 1 的反应函数为
\beta_1(q_2) = \begin{cases} (a - c - q_2) / 2 & \text{if } \ q_2 \leq a - c \\ 0 & \text{if } \ q_2 > a - c \end{cases}
参与人 2 的反应函数也可以用相同方法计算,结果为
\beta_2(q_1) = \begin{cases} (a - c - q_1) / 2 & \text{if } \ q_1 \leq a - c \\ 0 & \text{if } \ q_1 > a - c \end{cases}
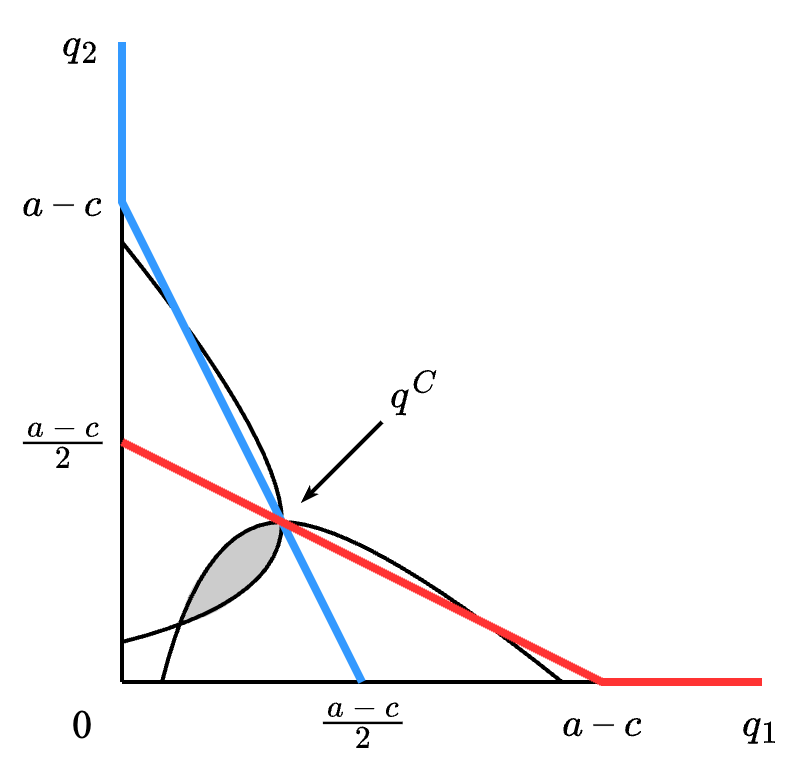
我们将这两个反应函数绘制在 Figure 6.1 中。纳什均衡是反应函数的交点,可以通过解方程组 q_1 = (a - c - q_2) / 2 和 q_2 = (a - c - q_1) / 2 获得,结果为
(q_1^C, q_2^C) = \Big( \frac{a-c}{3}, \frac{a-c}{3} \Big) .
6.2.1.1 帕雷托最优解
如果对于策略组合 (q_1, q_2) 来说,找不到能保证两个参与人的收益都不减少,同时至少能使一人的收益增加的其他策略组合 (q_1', q_2'),则 (q_1, q_2) 是帕雷托最优策略。你无需感到惊讶,均衡策略 (q_1^C, q_2^C) 不是帕雷托最优。例如,两个参与人通过解下面的联合利润最大化问题都能获取更高的利润:
\max_{q_1, q_2 \geq 0} \Pi_1(q_1, q_2) + \Pi_2(q_1, q_2).
此问题可以转化为
\max_{q_1, q_2 \geq 0} (q_1 + q_2)(a - c - q_1 - q_2)
或者通过令 Q = q_1 + q_2 改写为
\max_{q_1, q_2 \geq 0} Q(a - c - Q)
最优解为 Q = (a - c) / 2。这恰好是垄断时的总产量。因此,联合利润最大化可以通过任何满足 q_1 + q_2 = (a - c) / 2 的组合 (q_1, q_2) \geq \boldsymbol{0} 达成。例如当 q_1 = q_2 = (a-c) / 4 时,每个参与人的利润为 (a - c)^2 / 8,而纳什均衡中每人的利润为 (a-c)^2 / 9。在 Figure 6.1 中用阴影画出了所有帕雷托优于纳什均衡的策略组合,即保证两个参与人的收益都不少于纳什均衡,同时至少能使一人的收益增加。
6.2.2 不完全信息下的简化版模型
以 Section 6.2.1 中古诺模型为基础,现在假设企业 2 的边际成本或为高成本 c_H,或为低成本 c_L,c_H > c_L > 0。企业 2 知道自身的边际成本,但是企业 1 只知道高成本 c_H 的概率为 \vartheta,低成本 c_L 的概率为 1 - \vartheta。企业 1 的边际成本 c > 0 为共同知识。根据 Section 5.1 的方法论,此设定相当于参与人 1 仅有一个类型,但参与人 2 有两个类型 c_H 和 c_L。此博弈的定义如下:
参与人集合为 N = \{1,2\}。
参与人 1 的策略集合为 S_1 = [0,\infty),并用 q_1 代表具体的策略。参与人 2 的策略集合是 S_2 = [0, \infty) \times [0, \infty),并用 (q_H, q_L) 代表具体的策略。顾名思义,q_H 是类型为 c_H 时参与人 2 选择的产量,而 q_L 是类型为 c_L 时他选择的产量。
收益函数为期望收益函数,即
\Pi_i(q_1, q_H, q_L) = \vartheta \Pi_i(q_1, q_H) + (1 - \vartheta) \Pi_i(q_1, q_L) , \quad i = 1, 2,
其中 \Pi_i(\cdot, \cdot) 是 Section 6.2.1 中的期望函数。
为了找到贝叶斯纳什均衡,我们首先计算参与人 1 的最佳响应(反应)函数。这可以通过在固定 q_H 和 q_L 的情况下在 q_1 \geq 0 的范围内最大化 \Pi_1(q_1, q_H, q_L) 完成。具体的最大化问题是
\max_{p_1 \geq 0} \vartheta \big[q_1 (a - c - q_1 - q_H)\big] + (1 - \vartheta) \big[q_1 (a - c - q_1 - q_L)\big] .
假设 q_H, q_L \leq a - c(在解出均衡后需要验证此假设是否成立),通过解一阶条件可得
q_1 = q_1(q_H, q_L) = \frac{a - c - \vartheta q_H - (1-\vartheta) q_L}{2} .
对比上一节的结果 q_1 = (a - c - q_2) / 2,此处用期望产量 \vartheta q_H + (1 - \vartheta) q_L 替代了 q_2,这源自模型的线性设定。
而对于参与人 2,我们需要在固定 q_1 的情况下解下面的最大化问题
\max_{q_H, q_L \geq 0} \vartheta \big[q_H (a - c_H - q_1 - q_H)\big] + (1 - \vartheta) \big[q_L (a - c_L - q_1 - q_L)\big] .
由于目标函数中的第一项仅依赖 q_H 而第二项仅依赖 q_L,我们可以将两项分别当作一个目标函数进行最大化,也就是针对类型 c_H 和 c_L 分别计算反应函数1 。假设 q_1 \leq a - c_H(自然满足 q_1 \leq a - c_L,注意后面需要验证是否成立),可得
1 这在不完全信息贝叶斯博弈中是普遍成立的,即对一个参与人的所有类型的期望收益进行最大化等价于对每个类型的收益分别进行最大化。
\begin{align*} q_H &= q_H(q_1) = \frac{a - c_H - q_1}{2}, \\ q_L &= q_L(q_1) = \frac{a - c_L - q_1}{2}. \end{align*}
通过解三个反应函数的联立方程可得纳
\begin{align*} q_1^C &= \frac{a - 2c + \vartheta c_H + (1 - \vartheta) c_L}{3}, \\ q_H^C &= \frac{a - 2c_H + c}{3} + \frac{1 - \vartheta}{6}(c_H - c_L), \\ q_L^C &= \frac{a - 2c_L + c}{3} - \frac{\vartheta}{6}(c_H - c_L). \end{align*}
当参数值满足 q_1^C, q_H^C, q_L^C \geq 0, q_1 \leq a - c_H 以及 q_H, q_L \leq a - c 时,(q_1^C, q_H^C, q_L^C) 即是此博弈的贝叶斯纳什均衡。
6.3 伯特兰价格竞争模型
继续假设两个企业生产同一种产品。在这一节中我们假设此产品的需求函数在价格为 p \geq 0 时为 q(p) = \max \{a-p, 0\},其中常数 a >0 是价格为零时的需求量。能够提供更低价格的企业将垄断整个市场,但如果双方的价格相同则平分市场。每个企业的边际成本都是 0 \leq c < a,且没有固定成本。如果企业 1 将价格定为 p_1,企业 2 将价格定为 p_2,则企业 1 的利润函数为
\Pi_1(p_1, p_2) = \begin{cases} (p_1 - c)(a - p_1) & \text{if } \ p_1 < p_2 \text{ and } p_1 \leq a \\ \frac{1}{2} (p_1 - c)(a - p_1) & \text{if } \ p_1 = p_2 \text{ and } p_1 \leq a \\ 0 & \text{otherwise} \end{cases}
企业 2 的利润函数为
\Pi_2(p_1, p_2) = \begin{cases} (p_2 - c)(a - p_2) & \text{if } \ p_2 < p_1 \text{ and } p_2 \leq a \\ \frac{1}{2} (p_2 - c)(a - p_2) & \text{if } \ p_1 = p_2 \text{ and } p_2 \leq a \\ 0 & \text{otherwise} \end{cases}
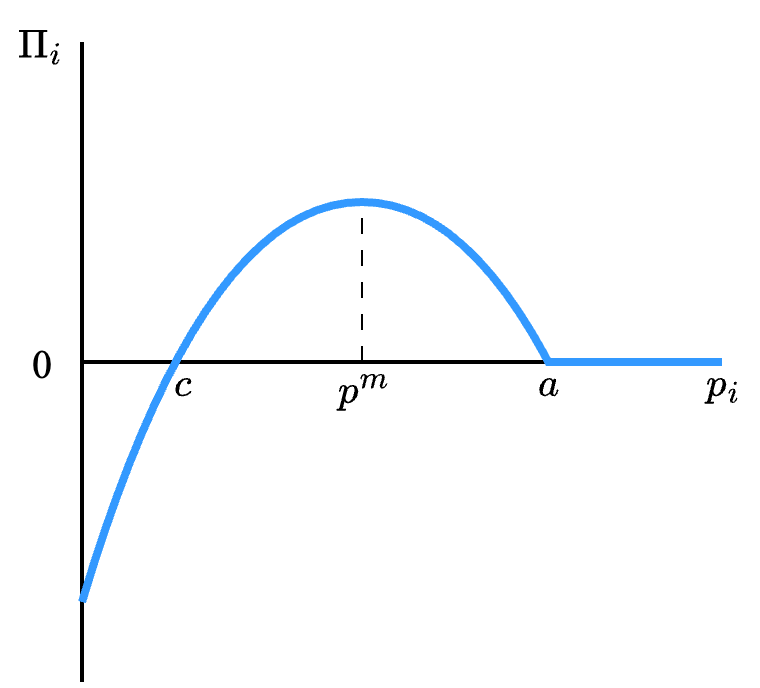
和上一节一样,两个企业为博弈的参与人,其利润函数为收益函数,每个参与人的策略集合为 [0, \infty),用 p_1, p_2 代表二人的策略。为找到纳什均衡(伯特兰均衡),我们依然从计算反应函数开始。在这个模型中,垄断时令利润最大化的价格 p^m = (a+c) / 2 将发挥重要作用,这是通过解最大化问题
\max_{p \geq 0} (p-c)(a-p)
得到的。注意垄断时的利润函数是二次函数(见 Figure 6.2)。
下面计算参与人 1 的反应函数 \beta_1(p_2)。这包含以下几种情形:
如果 p_2 < c,则任何 p_1 \leq p_2 都会给参与人 1 带来负收益,任何 p_1 > p_2 的收益都为零。因此此时的最佳响应策略集合为 (p_2, \infty)。
如果 p_2 = c,则任何 p_1 < p_2 都会给参与人 1 带来负收益,任何 p_1 \geq p_2 的收益都为零。因此此时的最佳响应策略集合为 [c, \infty)。
如果 c < p_2 \leq p^m,则最佳响应应 p_2(为了取得垄断地位)且尽可能地靠近 p^m(为了获得更多收益),但不存在这样的价格,因为对于任何 p_1 < p_2,介于 p_1 和 p_2 之间的价格都会带来更多收益。因此,此时的最佳响应策略集合为空集2。
如果 p_2 > p^m,则唯一的最佳响应策略是 p^m。
2 如果价格不是连续变量而是存在最小单位,那么就可以避免此结果。
综上所述,参与人 1 的反应函数为
\beta_1(p_2) = \begin{cases} \{p_1 \mid p_1 > p_2\} & \text{if } \ p_2 < c \\ \{p_1 \mid p_1 \geq c\} & \text{if } \ p_2 = c \\ \emptyset & \text{if } \ c < p_2 \leq p^m \\ \{p^m\} & \text{if } \ p_2 > p^m \end{cases}
类似分析同样适用于参与人 2,因此可得
\beta_2(p_1) = \begin{cases} \{p_2 \mid p_2 > p_1\} & \text{if } \ p_1 < c \\ \{p_2 \mid p_2 \geq c\} & \text{if } \ p_1 = c \\ \emptyset & \text{if } \ c < p_1 \leq p^m \\ \{p^m\} & \text{if } \ p_1 > p^m \end{cases}
严格意义上讲,这里的 \beta_1(\cdot) 和 \beta_2(\cdot) 不是函数(function),因为我们允许它的值是集合。像这样可以给变量赋予集合值的映射关系在数学上称为对应(correspondence)。
两个函数的交集可以通过绘图或者直接验证的方式获得,下面我们进行验证,而你可以自己尝试绘图的方法。
如果 p_2 < c,则由 \beta_1(p_2) 可得 p_1 > p_2。此时根据 \beta_2(p_1) 可知 p_2 = p^m,但是和 p^m > c 矛盾。因此在均衡中 p_2 \geq c。
如果 p_2 = c,则根据 \beta_1(p_2) 可得 p_1 \geq c。此时如果 p_1 > c,则根据 \beta_2(p_1),唯一的可能性是 p_2 = p^m,依然和 p^m > c 矛盾。因此只有 p_1 = c 成立。p_1 = p_2 = c 是纳什均衡。
如果 p_2 > c,则根据 \beta_1(p_2) 可得 p_1 = p^m。但此时参与人 2 没有最佳响应。
因此,(c, c) 是此博弈唯一的纳什(伯特兰)均衡。
我们也可以在不计算反应函数的情况下求得此均衡。假设在均衡中 p_1 \neq p_2。根据问题的对称性,我们只需分析 p_1 < p_2 的情况。如果 p_1 < p^m,则参与人 1 可以通过提高价格(但不高过 p_2)的方式提升收益。如果 p_1 = p^m,则参与人 2 可以通过设定 p_2 = p^m 的方式提升收益。如果 p_1 > p^m,则参与人 2 课题通过设定一个略小于 p_1 的价格以提升收益。因此均衡需满足 p_1 = p_2。如果这个统一价格低于 c,则双方都获得负收益,此时每个参与人都可以通过涨价而获得零收益。如果统一价格高于 c,每个参与人也可以通过略微降价占领市场而提升收益。因此唯一的可能性是 p_1 = p_2 = c,此时双方的收益都为零,任意一方如果涨价则失去市场份额(收益依然为零),如果降价则形成垄断但收益为负。因此 p_1 = p_2 = c 是均衡价格。
关于这个均衡有几点补充。首先,它也是帕雷托劣势策略。例如双方都将价格设为 p^m 就都能获得正收益。第二,每个参与人的策略都是弱劣势策略:任意价格 c < p_i < a 都弱优于 p_i = c,因为此时的收益为正或者零,但 p_i = c 的收益永远为零。第三,伯特兰均衡对于消费者来说是最好的,因为它将消费者剩余最大化。
6.4 斯塔克尔伯格均衡
在 Section 6.2.1 的古诺模型中,两个企业需要同时决定产量。现在我们假设企业 1 首先进行决策,企业 2 在观察到企业 1 的行动后再进行决策。此设定已经在 Chapter 1 中讨论过。Figure 6.3 给出了它对应的扩展式博弈。
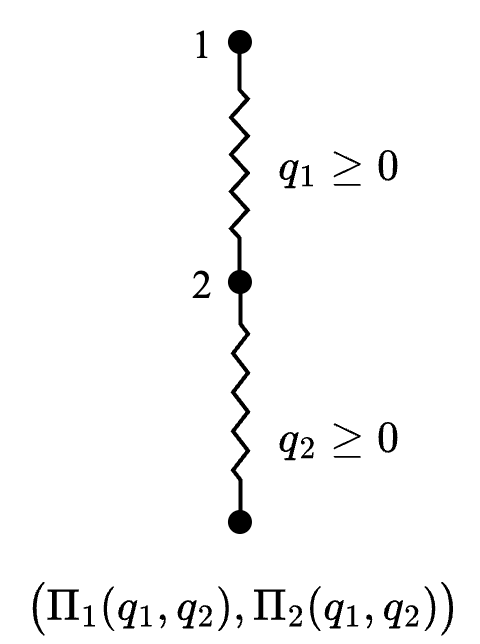
3 参与人 2 的策略集表达为 [0,\infty)^{[0,\infty)}。
在此博弈中,参与人 1 拥有无限行动/策略集 [0, \infty),以 q_1 代表具体策略。在图中我们用锯齿线代表无限行动集。参与人 2 的行动集也是 [0,\infty),以 q_2 代表具体策略,在图中的表达方式相同。参与人 2 的策略是给他的每个信息集赋予一个对应的行动。而参与人 1 的每一种选择 q_1 都伴随着参与人 2 的一个信息集,因此参与人 2 的策略是一个函数 s_2 : [0, \infty) \to [0, \infty)。如果参与人 1 选择产量 q_1,则参与人 2 的策略表达为 q_2 = s_2(q_1)。显然,参与人 2 的策略集也是无限的3。适合此博弈的解是利用逆向归纳法的子博弈完美均衡。子博弈包括博弈本身以及以参与人 2 的决策节点为起点的每个单人博弈。根据逆向归纳法,在参与人 1 选择 q_1 后,参与人 2 在随后的单人博弈中都应作出最优选择,这意味着他需要根据 Section 6.1 中得出的反应函数 \beta_2(q_1) 进行决策。然后回到整个博弈的起点,参与人 1 需要考虑参与人 2 的最佳响应,因此选择令 \Pi_1(q_1, \beta_2(q_1)) 最大化的 q_1 \geq 0。我们可以轻松确认 q_1 > a-c 时不存在最优解,而当 q_1 \leq a - c 时,参与人 1 的目标函数表达为
q_1\Big(a - c - q_1 -\frac{a - c - q_1}{2} \Big) .
最优解为 q_1 = (a - c) / 2,对应的 q_2 = \beta_2\big((a-c) / 2\big) = (a-c) / 4。因此,子博弈完美均衡(注意这是一个策略组合)为
q_1 = \frac{a-c}{2}, \quad q_2 = \beta_2(q_1) . 而均衡的结果(outcome)是执行均衡策略时参与人们选择的行动路径,在这里均衡结果为
q_1^S = \frac{a-c}{2}, \quad q_2^S = \frac{a-c}{4} .
上角标的 S 对应斯塔克尔伯格 Stackelberg 的首字母。这个子博弈完美均衡也被称为斯塔克尔伯格均衡。这里因为我们假设参与人 1 为先行者(leader),可以确认他的收益要大于古诺均衡带来的收益,而参与人 2 作为追随者(follower),其收益则小于古诺均衡时的收益。
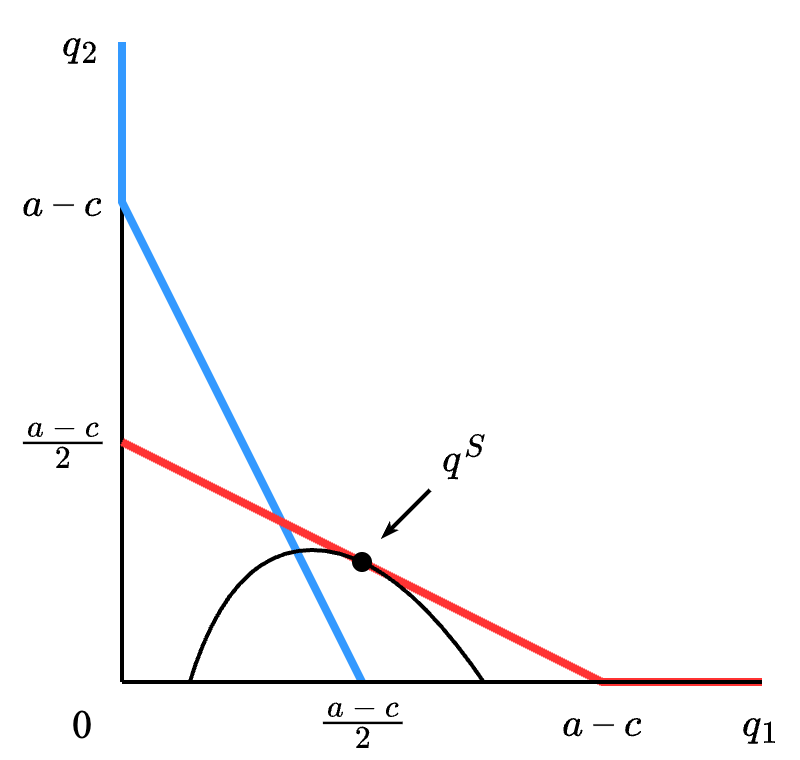
Figure 6.4 绘制了斯塔克尔伯格均衡的位置。参与人 1 (先行者)在参与人 2 的(追随者)的反应函数上选择令自己收益最大的点,因此参与人 2 在自己的反应函数上,而参与人 1 不在。
6.5 拍卖
拍卖(auction)是利用规定好的流程将商品卖给感兴趣的买家的交易方式,而商品的价格就由拍卖的方法决定。拍卖的例子包括艺术品交易(通常为增价拍卖,也叫英格兰式拍卖4),鲜花交易(通常为减价拍卖,也叫荷兰式拍卖),公共事业招投标,以及移动通信的频谱拍卖等。
4 拍卖相关术语的中文译文参考了中华人民共和国商务部发布的中华人民共和国国内贸易行业标准 SB/T 10641-2018《拍卖术语》。不包含在此标准中的学术术语采用通用译法。
在本节中我们将讨论几个简单的古典交易模型。首先介绍的是完全信息下的第一价格和第二价格投标式(sealed bid,即密封出价)拍卖,随后是不完全信息下的第一价格投标式拍卖,最后是买家和卖家间的双向拍卖(double auction)。
6.5.1 完全信息
假设有 n 个人都想获得一个不可分割的物品。每个人 i 都对该物品进行了估值,记为 v_i > 0。这里不失一般性地假设 v_1 \geq v_2 \geq \dots \geq v_n。在第一价格投标式拍卖(first-price sealed-bid auction)中,每个竞买人(bidder)都需提出一个报价(bid)b_i \geq 0,而所有报价都需要同时且独立地提出(因此称为密封出价,sealed-bid)。给出最高报价的竞标人将以自身的报价价格购得该物品,因此称为第一价格(first-price)拍卖。如果出现最高报价者多于一人的情况,则规定其中序号最小的赢得拍卖。注意这只是一种打破平局的方法,也可以在不影响基本结论的情况下替换为其他方法。
从以上设定我们可以定义博弈:参与人集合为 N=\{1, \dots, n\},每个参与人 i 的策略集为 S_i = [0,\infty),具体策略记作 b_i。参与人 i 的收益函数5为
5 这里也假设了每个参与人都了解整个博弈,意味着他们知道其他参与人对该物品的估值。
u_i(b_1, \dots, b_i, \dots, b_n) = \begin{cases} v_i - b_i & \text{if } \ i = \min \{k \in N \mid b_k \geq b_j \text{ for all } j \in N\} \\ 0 & \text{otherwise} . \end{cases}
此博弈的一个纳什均衡是 (b_1, \dots, b_n) = (v_2, v_2, v_3, \dots, v_n)。根据博弈的定义,在此策略组合下参与人 i \neq 1 无法赢得拍卖,因此且收益为零。降低报价依然无法获胜,而通过提高报价获胜最终只能获得负收益,因此没有更好的策略。参与人 1 在此策略组合下会赢得拍卖并获得收益 v_1 - v_2 \geq 0,而如果降低报价则无法赢得拍卖(收益降为零),提高报价虽然依旧会获胜但收益将小于 v_1 - v_2,因此参与人 1 也没有更好的策略。在此均衡中,参与人 1 的报价是参与人 2 的估价,也就是第二高的估价。这也会发生在英式拍卖和荷式拍卖中。
除此之外,这个博弈还存在很多纳什均衡,但是在任意均衡中胜者都是对拍卖品估值最高的参与人(之一)。将报价设在自身估值或高于自身估值的策略是弱劣势策略,但设在低于自身估值的策略不是弱劣势策略。你能证明这些性质吗?
第二价格投标式拍卖与第一价格投标式拍卖的唯一不同之处是胜者需要支付第二高的报价。如果最高报价者多于一人,则其中序号最小的获胜且支付自身的报价。这种拍卖的主要性质是,对于每个参与人 i,将报价设为自身估值的策略,即 (b_1, \dots, b_n) = (v_1, \dots, v_n),是弱优势策略,也是一个纳什均衡。
6.5.2 不完全信息
这里我们对 Section 6.5.1 的设定做少许修正,假设每个竞买人知道自身的估值,但对其他人的估值仅有分布意义上的知识。如果将竞买人的估值视作类型,这意味着每个竞买人会对其他竞买人的类型组合赋予一个概率分布。为了简化设定,我们假设每个竞买人的类型都从区间 [0,1] 上的均匀分布独立产生,且这是共同知识,且每个竞买人都了解自身的真实类型。拍卖的种类依然是第一价格投标式拍卖。虽然我们无法给出固定的估值排序,我们依然可以假设与上一节相同的打破平局的规则。
这里我们只讨论两个竞买人的情形,而你可以自己尝试探索 n > 2 时的性质。在这个拍卖对应的二人博弈中,参与人 i \in \{1,2\} 的策略需要对自身的每一个可能的类型赋予一个报价。由于可能的类型集合为 [0,1],同时没有理由报高于 1 的价格,因此策略是函数 s_i: [0,1] \to [0,1]。也就是说如果参与人 i 的类型是 v_i,则其在采用策略 s_i 时的报价是 b_i = s_i(v_i)。参与人 i 的收益函数给每个策略组合 (s_i, s_j) 赋予 i 在此策略下的期望收益。在纳什均衡中,每个参与人都在固定对方策略的前提下选择令自身期望收益最大化的策略。而每个参与人的每个类型都在固定对方策略的前提下最大化自身期望收益是纳什均衡的充分条件。用 Chapter 5 中的话说,就是贝叶斯均衡一定是纳什均衡6。
6 纳什均衡不一定是贝叶斯均衡。两者的区别在于,在纳什均衡中,概率为零的类型可以不选择最佳响应策略,因为这并不会改变期望收益。
此博弈的一个纳什均衡是 s_1^* (v_1) = v_1 / 2, s_2^* (v_2) = v_2 / 2。为了证明此结论,我们首先在固定参与人 2 的策略 s_2^* 的情况下考虑参与人 1 的类型 v_1。如果参与人 1 的报价为 b_1,则参与人 1 获胜的概率等于参与人 2 的报价不高于 b_1 的概率。这个概率等于 \mathrm{Prob} [v_2 / 2 \leq b_1] = \mathrm{Prob}[v_2 \leq 2b_1]。根据 s_2^* 的定义可知参与人 2 的报价不会高于 1/2,因此可以进一步假设 b_1 \leq 1/2。由于 v_2 服从 [0,1] 上的均匀分布,且 2b_1 \leq 1,可知 \mathrm{Prob}[v_2 \leq 2b_1] = 2b_1。也就是说,当参与人 2 的策略是 s_2^* 时,参与人 1 以报价 b_1 获胜的概率等于 2b_1,因此期望收益是 2b_1 (v_1 - b_1)。当 b_1 = v_1 / 2 期望收益最大,因此 s_1^* (v_1) = v_1 / 2 是 s_2^* 的最佳响应。相反情况下的分析也非常类似,唯一的区别是参与人 2 获胜需要参与人 1 的报价严格低于参与人 2 的报价,但这在均匀分布下不会改变概率值。
在均衡 s_1^* (v_1) = v_1 / 2, s_2^* (v_2) = v_2 / 2 中每个竞买人的报价仅是各自估值的一半。估值更高者赢得拍卖。
那么不完全信息第二价格投标式拍卖呢?此时的结论更加简单,将报价设为各自的估值对每个参与人来说都是弱优势策略,因此 s_i^* (v_i)= v_i, i \in N 是贝叶斯纳什均衡。
6.5.3 不完全信息下的双向拍卖
假设有买家和卖家两个参与人。卖家拥有拍卖品,并对其估值为 v_s。买家对拍卖品的估值为 v_b。假设这两个估值都从区间 [0,1] 上的均匀分布独立产生。买家和卖家都知道各自自身的估值,但并不知道对方的估值,只知道对方的估值服从 [0,1] 上的均匀分布。
拍卖程序如下:买家和卖家同时独立给出价格 p_b 和 p_s。如果 p_b \geq p_s 则成交,成交价为平均报价 p = (p_b + p_s) / 2。买家获得收益 v_b - p,卖家获得收益 p - v_s。如果 p_b < p_s 则交易失败,买卖双方的收益均为零。
这是一个不完全信息博弈。买家有无穷多个类型 v_b \in [0,1],卖家亦然 v_s \in [0,1]。策略是给每个类型赋予一个报价的函数。买家的策略为 p_b: [0,1] \to [0.1],即 p_b(v_b) 是当其类型为 v_b 时的报价。同样,卖家的策略为 p_s: [0,1] \to [0,1],即 p_s(v_s) 是当其类型为 v_s 时的报价。
假设卖家选择的策略是 p_s(\cdot)。此时买家的期望收益是其估值 v_b 和报价 p_b 的函数
\Bigg[ v_b - \frac{p_b + E[p_s(v_s) \mid p_b \geq p_s(v_s)]}{2} \Bigg] \mathrm{Prob}[p_b \geq p_s(v_s)]
其中 E[p_s(v_s) \mid p_b \geq p_s(v_s)] 是在卖家的报价不高于买家报价的条件下,买家基于策略 p_s(\cdot) 得出的卖家报价的期望值。
同理,假设买家选择的策略是 p_d(\cdot)。此时卖家的期望收益是其估值 v_s 和报价 p_s 的函数
\Bigg[ \frac{p_s + E[p_b(v_b) \mid p_s \leq p_b(v_b)]}{2} - v_s \Bigg] \mathrm{Prob}[p_s \leq p_b(v_b)]
其中 E[p_b(v_b) \mid p_s \leq p_b(v_b)] 是在买家的报价不低于卖家报价的条件下,卖家基于策略 p_b(\cdot) 得出的买家报价的期望值。
此时,策略组合 \big(p_b(\cdot), p_s(\cdot)\big) 成为(贝叶斯)纳什均衡的条件是,对任意 v_b \in [0,1],p_b(v_b) 是最大化问题
\max_{p_b \in [0,1]} \Bigg[ v_b - \frac{p_b + E[p_s(v_s) \mid p_b \geq p_s(v_s)]}{2} \Bigg] \mathrm{Prob}[p_b \geq p_s(v_s)]
的解,同时对任意 v_s \in [0,1],p_s(v_s) 是最大化问题
\max_{p_s \in [0,1]} \Bigg[ \frac{p_s + E[p_b(v_b) \mid p_s \leq p_b(v_b)]}{2} - v_s \Bigg] \mathrm{Prob}[p_s \leq p_b(v_b)]
的解。
此博弈拥有很多纳什均衡。在理想状态下,只要交易是有效的,即 v_b \geq v_s,就都应该成交。但事实上在满足 v_b \geq v_s 时,不同策略组合的成交概率不同。并不是所有的纳什均衡都同样有效,有的均衡策略的成交概率高于其他均衡策略。
你能证明下面的策略组合是纳什均衡吗?
x \in [0,1], \quad p_b(v_b) = \begin{cases} x & \text{if } \ v_b \geq x \\ 0 & \text{if } \ v_b < x \end{cases}, \quad p_s(v_s) = \begin{cases} x & \text{if } \ v_s \leq x \\ 0 & \text{if } \ v_s > x \end{cases}
6.6 混合策略与不完全信息
在这一节中,我们将探讨双矩阵博弈的混合策略纳什均衡和由该博弈引申出的一系列不完全信息博弈的贝叶斯纳什均衡的极限间的等价关系。
考虑下面的双矩阵博弈
\begin{align*} & \ \ \ \ \, \begin{matrix} L & \ \ \, R \end{matrix} \\ \begin{matrix} T \\ B\end{matrix} & \begin{pmatrix} 2,1 & 2,0 \\ 3,0 & 1,3 \end{pmatrix} \end{align*}
此博弈的唯一纳什均衡是 \big( (p^*, 1-p^*), (q^*, 1-q^*) \big), p^* = 3/4, q^* = 1/2。如何解释混合策略以及混合策略纳什均衡的现实含义是博弈论领域的一个古典问题。一种解释是参与人真的按照均衡策略给出的概率分布进行选择。虽然有一些实证研究认为这能够在现实中发生7,这种解释也并没有很强的说服力,特别是在混合策略纳什均衡中,所有发生概率为正的纯策略给参与人带来的收益都想等。另一个解释(在 Section 3.1 中曾经提到过)是混合策略代表其他参与人对自己选择纯策略行为的信念。例如在上面的均衡中,参与人 2 相信参与人 1 以 3/4 的概率选择策略 T。这中解释的缺点是这些信念是主观的,而且并没有说明它们如何形成。在这一节中,我们探讨一种获得混合策略纳什均衡的方法,即给博弈添加一些客观的不确定性,计算计算贝叶斯纳什均衡的极限。也就是将表达为信念的主观不确定性替换成随机选择的客观不确定性。
7 例如 Walker and Wooders (2001)。
在上面的例子里,假设参与人 1 从 (T,L) 获得的收益变成不确定的 2 + \alpha,而参与人 2 从 (B,R) 获得的收益也变成不确定的 3 + \beta。假设 \alpha 和 \beta 都服从 [0,x] 上的独立均匀分布,x > 0。在随机选择后,参与人 1 知道 \alpha 的取值,参与人 2 知道 \beta 的取值,而且这是共同知识。换句话说,参与人 1 知道自己的类型 \alpha,参与人 2 知道自己的类型 \beta。新的收益矩阵是
\begin{align*} & \ \ \ \ \ \ \ \, \begin{matrix} L & \ \ \ \ \ \ \ \ \ \ \, R \end{matrix} \\ \begin{matrix} T \\ B\end{matrix} & \begin{pmatrix} 2+\alpha,1 & 2,0 \\ 3,0 & 1,3+\beta \end{pmatrix} \end{align*}
参与人 1 的策略是函数 s_1: [0,x] \to \{T, B\},参与人 2 的策略是函数 s_2: [0,x] \to \{L,R\}。
下面我们尝试找出此博弈的均衡。假设参与人 2 的策略是当 \beta 很小时选择 L,很大时选择 R。具体的说就是假设存在一个 b \in [0,x] 满足 \beta \leq b 时参与人 2 选择 L,而 \beta > b 时选择 R。将此策略记作 s_2^b。此时参与人 1 的最佳响应是什么?假设参与人 1 的类型是 \alpha,那么当他选择 T 时,期望收益为
(2+\alpha) \cdot \frac{b}{x} + 2 \cdot (1 - \frac{b}{x}) = 2 + \alpha \cdot \frac{b}{x},
而当他选择 B 时,期望收益为
3 \cdot \frac{b}{x} + 1 \cdot (1 - \frac{b}{x}) = 1 + 2 \cdot \frac{b}{x} .
因此,T 不比 B 差的条件是 \alpha \geq (2b - x) / b。参与人 1 对 s_2^b 的最佳响应是:当 \alpha \geq a 是选择 T,而 \alpha < a 时选择 B,a = (2b-x) / b。将此策略记作 s_1^a。
反之,假设参与人 1 选择策略 s_1^a。参与人 2 的最佳响应可以由相同方式计算。如果类型 \beta 的参与人 2 选择 L,则期望收益为
1 \cdot (1-\frac{a}{x}) + 0 \cdot \frac{a}{x} = 1 - \frac{a}{x} ,
而当他选择 R 时,期望收益为
0 \cdot (1 - \frac{a}{x}) + (3+\beta) \cdot \frac{a}{x} = (3+\beta) \cdot \frac{a}{x} .
因此,L 不比 R 差的条件是 \beta \leq (x - 4a) / a。因此参与人 2 对 s_1^a 的最佳响应是 s_2^b,b = (x-4a)/a。
综上所述,当 a = (2b-x)/b, b = (x-4a)/a 时,策略组合 (s_1^a, s_2^b) 是纳什均衡。在 [0,x] 范围内解方程组可得
a = \frac{1}{4} (x + 4 - \sqrt{x^2 + 16}), \quad b = \frac{1}{2} (x - 4 + \sqrt{x^2 + 16}).
在这个均衡中,参与人 1 选择 T 的先验概率(即在他了解自己的类型之前的概率)是 1-a/x = (\sqrt{x^2 + 16} + 3x - 4)/(4x),而参与人 2 选择 L 的先验概率是 b/x = (x - 4 + \sqrt{x^2 + 16}) / (2x)。当不确定性越来越小,即 x \to 0 时,这两个概率的极限值是多少呢?对于参与人 1,
\lim_{x\to 0} \frac{\sqrt{x^2 + 16} + 3x - 4}{4x} = \lim_{x\to 0} \frac{x/\sqrt{x^2 + 16} + 3}{4} = \frac{3}{4},
注意第一个等式应用了洛必达法则。而对于参与人 2,
\lim_{x\to 0} \frac{x - 4 + \sqrt{x^2 + 16}}{2x} = \lim_{x\to 0} \frac{1 + x / \sqrt{x^2 + 16}}{2} = \frac{1}{2} .
可见,这两个概率收敛于原博弈的混合策略纳什均衡。
6.7 序贯议价
最简化的讨价还价问题(bargaining problem)包含两个当事人,他们需要从一组备选方案中就选择哪个方案达成共识。如果他们不能达成共识,则将执行一个特殊的分歧(disagreement)方案。博弈论中对讨价还价问题由两种主流方法,一种是基于合作博弈的方法(也称为纳什谈判问题),另一种是基于非合作博弈的方法(以鲁宾斯坦 Rubinstein 提出的交替报价博弈为代表)。这一节中我们讨论非合作博弈的方法,但也会言及它和纳什谈判问题的关系。
6.7.1 有限回合的讨价还价
这里我们继续 Section 1.3.5 中的讨价还价问题。该问题中,两个参与人针对如何分配一个单位的完美可分割物品(例如一升葡萄酒)进行讨价还价。如果无法达成共识,则假设双方的分配都为零。为了简化设定,这里假设两个参与人的偏好都以线性效用函数 u_1(\alpha) = u_2(\alpha) = \alpha, \alpha \in [0,1] 描述,即 \alpha 单位的物品可以给参与人带来的效用为 \alpha。此时,可行的分配集是由 (0,0), (1,0), (0,1) 三点为顶点构成的三角形区域。
我们用下面的交替报价8程序对讨价还价的过程建模。假设共有 T+1 个回合,T \in \mathbb{N}。在初始回合(t=0),参与人 1 给出报价,这里以物品分割比例的形式呈现为 (\alpha, 1-\alpha),\alpha \in [0,1]。即参与人 1 获得 \alpha 单位,参与人 2 获得 1-\alpha 单位。参与人 2 可以接受或者拒绝这个提议,接受时物品以该比例分配后结束博弈,拒绝时则进入下一回合。在 t=1 回合,两个参与人的角色互换,由参与人 2 进行报价,参与人 1 决定接受或者拒绝。如果参与人 1 接受提议,则以该提议的比例进行分配后结束博弈,拒绝则进入下一回合。在 t=2 回合,参与人的角色继续互换并重复之前的操作。因此,每当回合数为偶数时由参与人 1 报价,而回合数为奇数时由参与人 2 进行报价。最后一个回合是 t=T,如果到达这个回合,则认为双方没有达成共识,执行分歧方案 (0,0) 后结束博弈。
8 这里将 offer 翻译成报价,但并不代表报出的一定是价格。在这个例子中,参与人报出的就是分配比例。
假设效用需要折现(discount)。即在 t 回合获得的效用 \alpha 通过折现因子 0 < \delta < 1 进行折现计算后,对应 t-1 回合的效用 \delta \alpha,对应 0 回合的效用 \delta^t \alpha。这体现了相同单位的物品获得的越早其价值也越高。
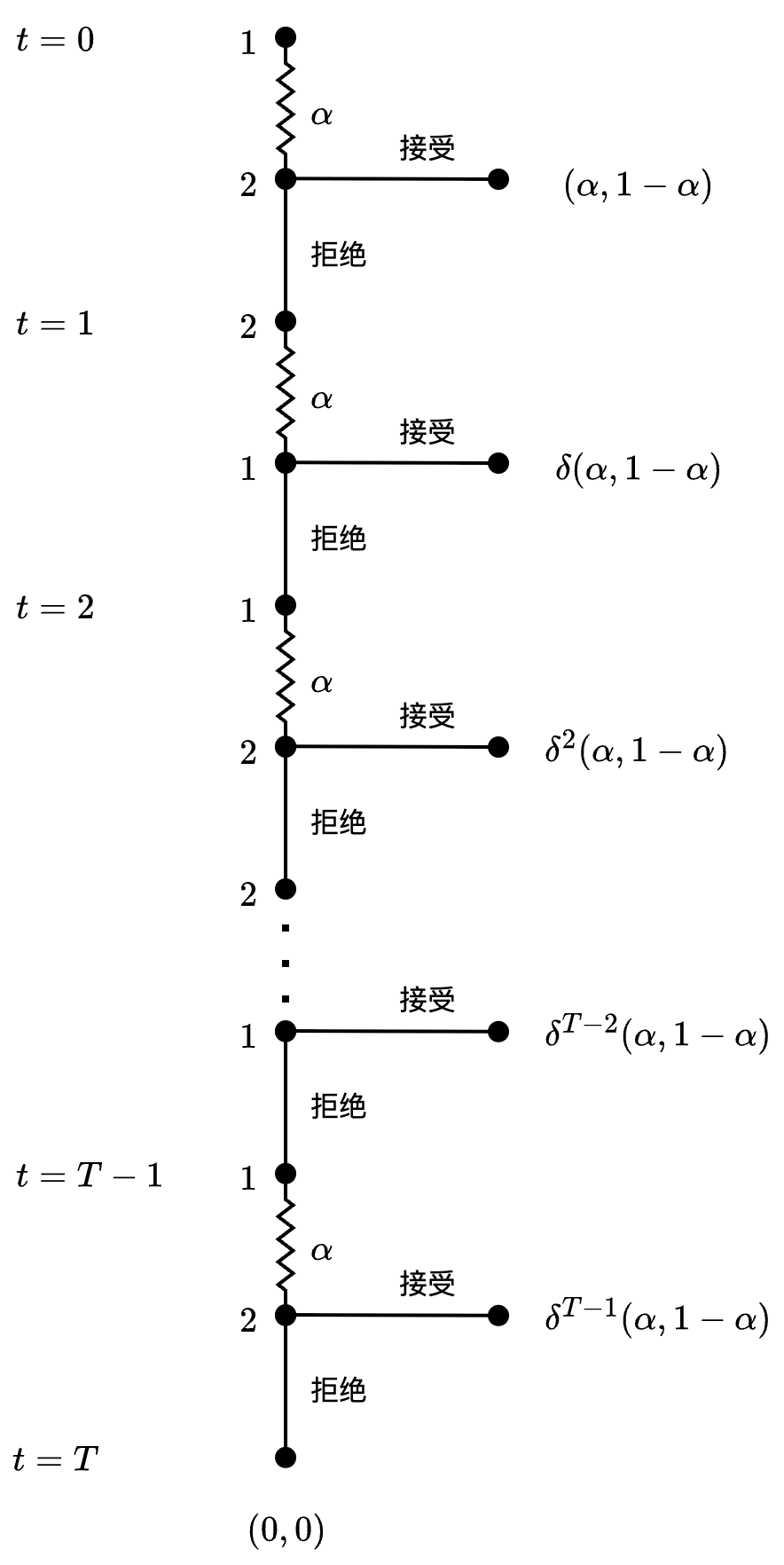
在 Figure 6.5 中我们能看到这个讨价还价过程对应的扩展式博弈。图中假设 T 为奇数,因此最后一个报价者为 T-1 回合的参与人 1。
下面我们通过逆向归纳法推导子博弈完美均衡。注意子博弈由决策节点开始,而 Figure 6.5 中的每个决策节点实际上包含了无数个子博弈,因为有无数条路径可以到达这些节点。
首先,在最后一个决策节点上,参与人 2 在 \alpha < 1 时都会选择接受,而在 \alpha = 1 时认为接受和拒绝没有区别。在 T-1 回合由参与人 1 报价的决策节点上,唯一的均衡是参与人 1 提议 \alpha = 1,然后参与人 2 接受任何提议。如果参与人 2 拒绝 \alpha - 1,则参与人 1 只要将提议改为 0 < \alpha < 1 即可增加自身的效用,因此只有在参与人 2 接受 \alpha = 1 时才能形成均衡,而参与人 1 的最佳选择是 \alpha = 1。据此,我们可以用收益组合 (\delta^{T-1}, 0) 替换博弈的 T-1 回合以后的部份,见 Figure 6.6。
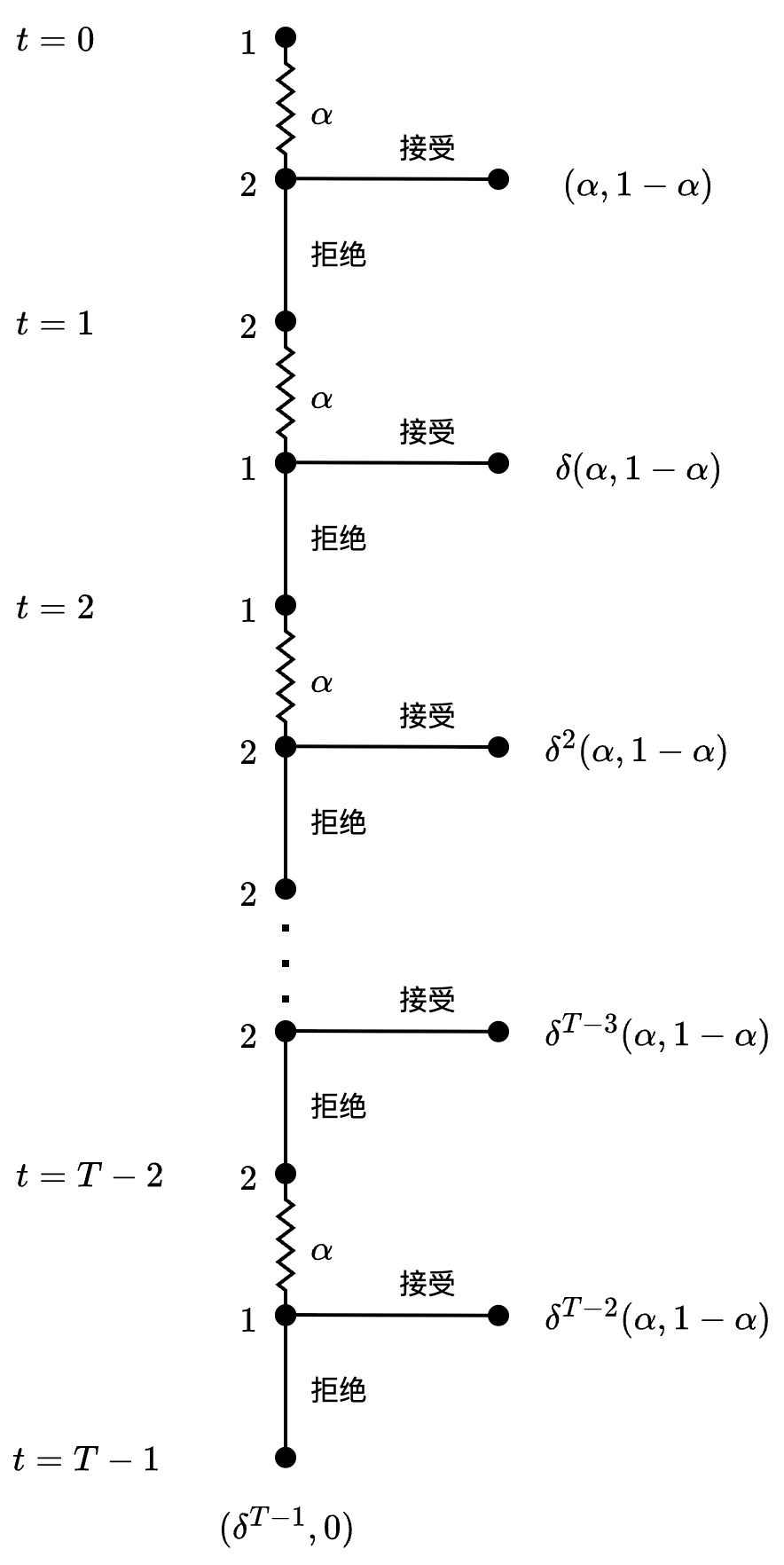
在缩短后的博弈的 T-2 回合的子博弈中,参与人 1 通过拒绝参与人 2 的提议可以获得的收益为 \delta^{T-1}。这是 t = T-1 时的效用 1 在 t=0 时的折现值,而其在 t = T-2 时的折现值是 \delta。因此,在均衡中参与人 2 的提议是 \alpha = \delta,然后参与人 1 选择接受 \alpha \geq \delta 但拒绝 \alpha < \delta。据此,我们可以用收益组合 (\delta^{T-2}\delta, \delta^{T-2}(1-\delta)) = (\delta^{T-1}, \delta^{T-2}(1-\delta)) 替换这个子博弈。通过重复这一逻辑可知,在 T-3 回合,参与人 1 提议 \alpha = 1 - \delta(1-\delta),而参与人 2 接受,对应的收益组合是 (\delta^{T-3}(1 - \delta(1-\delta)), \delta^{T-2}(1-\delta)) = (\delta^{T-3}(1 - \delta + \delta^2), \delta^{T-2}(\delta - \delta^2))。用同样方法可以继续将博弈缩短直至起始点。核心逻辑是每个参与人的提议只需分配给对方希望在下一回合获得的收益乘以 \delta 的值。
逆向追溯至 0 回合时,参与人 1 提议 \alpha = 1 - \delta + \delta^2 - \dots + \delta^{T-1}(见 Table 6.1),然后参与人 2 接受此提议。参与人 1 的收益为 1 - \delta + \delta^2 - \dots + \delta^{T-1},参与人 2 的收益为 \delta - \delta^2 + \dots - \delta^{T-1}。这是子博弈完美均衡策略的结果,也是均衡收益。子博弈完美均衡策略为:
在偶数回合 t,参与人 1 提议 \alpha = 1 - \delta + \dots + \delta^{T-1-t},参与人 2 接受任何不大于此 \alpha 的提议,但拒绝任何大于此 \alpha 的提议。
在奇数回合 t,参与人 2 提议 \alpha = \delta - \delta^2 + \dots + \delta^{T-1-t},参与人 1 接受任何不小于此 \alpha 的提议,但拒绝任何小于此 \alpha 的提议。
| 回合 | 报价人 | 参与人 1 的分配比例 | 参与人 2 的分配比例 |
|---|---|---|---|
| T | 0 | 0 | |
| T-1 | 1 | 1 | 0 |
| T-2 | 2 | \delta | 1-\delta |
| T-3 | 1 | 1-\delta+\delta^2 | \delta - \delta^2 |
| T-4 | 2 | \delta - \delta^2 + \delta^3 | 1 - \delta + \delta^2 -\delta^3 |
| \vdots | \vdots | \vdots | \vdots |
| 0 | 1 | 1-\delta + \delta^2 -\dots + \delta^{T-1} | \delta - \delta^2 + \dots - \delta^{T-1} |
6.7.2 无限回合的讨价还价
这一节里我们将上一节的讨价还价问题修改为拥有无限回合,即 T = \infty。如果没有达成共识,则两个参与人都无法获得任何收益。和有限回合讨价还价博弈一样,这个博弈也有很多纳什均衡。
分析无限回合讨价还价博弈的方法之一是从有限回合博弈出发计算 T=\infty 时的极限。事实上,这样获得的极限分配是子博弈完美均衡的唯一结果,但仅仅计算极限无法证明这一点。
在无限回合下,子博弈完美均衡不能通过逆向归纳法计算,因为该博弈没有最终决策节点。这里我们只能给出一组策略然后证明它是子博弈完美均衡。至于任意子博弈完美均衡都会产生相同结果的证明则需从文献中学习。
令 \boldsymbol{x}^* = (x_1^*, x_2^*) 和 \boldsymbol{y}^* = (y_1^*, y_2^*) 满足 x_1^2, x_2^*, y_1^*, y_2^* \geq 0, x_1^* + x_2^* = y_1^* + y_2^* = 1,并且
x_2^* = \delta y_2^*, \quad y_1^* = \delta x_1^* .
计算可得 \boldsymbol{x}^* = (1/(1+\delta), \delta / (1+\delta)),\boldsymbol{y}^* = (\delta / (1+\delta), 1 / (1+\delta))。考虑下面的策略组合:
参与人 1 的策略 \sigma_1^*:在回合 t = 0, 2, 4, \dots 提议 \boldsymbol{x}^*;在回合 t = 1, 3, 5, \dots 当且仅当参与人 2 的提议 (z_1, z_2) 满足 z_1 \geq \delta x_1^* 时接受它。
参与人 2 的策略 \sigma_2^*:在回合 t = 1, 3, 5, \dots 提议 \boldsymbol{y}^*;在回合 t = 0, 2, 4, \dots 当且仅当参与人 1 的提议 (z_1, z_2) 满足 z_2 \geq \delta y_2^* 时接受它。
这组策略是稳定的,即参与人每回合都提出相同的分配方案。而且每个参与人都会接受任何能给他带来不小于自己想获得收益的折现值的方案。根据 \boldsymbol{x}^* 和 \boldsymbol{y}^* 的定义,参与人 2 会接受 \boldsymbol{x}^*,而参与人 1 会接受 \boldsymbol{y}^*。因此,策略组合 (\sigma_1^*, \sigma_2^*) 的结果是在首轮 t=0 时参与人 1 提议 \boldsymbol{x}^* = (1/(1+\delta), \delta / (1+\delta)),随后被参与人 2 接受。这也是二人获得的收益。下面我们证明 (\sigma_1^*, \sigma_2^*) 是子博弈完美均衡。
此博弈中共有两类子博弈,一类是在起始节点参与人需要提出方案的,另一类是在起始节点参与人需要决定接受或者拒绝方案的。
对于第一类子博弈,我们可以不失一般性地考虑原博弈,即从 t=0 开始的博弈。我们需要证明 (\sigma_1^*, \sigma_2^*) 是纳什均衡。首先假设参与人 1 选择策略 \sigma_1^*。如果参与人 2 在 t=0 回合选择接受,他的收益就是 \delta/(1+\delta)。如果他选择拒绝,则针对 \sigma_1^*,他能够获得的最大收益是通过在 t=1 回合提议 \boldsymbol{y}^* 带来的 \delta/(1+\delta)。这是因为任何使 z_2 > y_2^* \Leftrightarrow z_1 < y_1^* 的提议 \boldsymbol{z} 都不会被参与人 1 接受。因此 \sigma_2^* 是 \sigma_1^* 的最佳响应。同理,如果参与人 2 选择 \sigma_2^*,则参与人 1 能够获得的最大收益是通过在 t=0 回合提议 \boldsymbol{x}^* 带来的 1/(1+\delta),因为参与人 2 会拒绝任何给参与人 1 带来更多收益的方案,同时也不会提出那样的方案。这说明 \sigma_1^* 也是 \sigma_2 的最佳响应。
对于第二类子博弈,我们也可以不失一般性地考虑原博弈,并假设参与人 1 已经提出了方案 \boldsymbol{z} = (z_1, z_2)。而对于奇数回合由参与人 2 报价的情形也可以用相同方法分析。首先假设在这个子博弈中参与人 1 选择策略 \sigma_1^*。如果 z_2 \geq \delta y_2^*,则接受 \boldsymbol{z} 会给参与人 2 带来回报 z_2 \geq \delta y_2^* = \delta / (1+\delta)。如果拒绝,则针对 \sigma_1^* 参与人 2 能够获得的最大回报是在 t=1 提议 \boldsymbol{y}^* 带来的 \delta / (1+\delta),这也会被参与人 1 接受。反之,如果 z_2 < \delta y_2^*,则参与人 2 选择拒绝然后在 t=1 提议 \boldsymbol{y}^* 能给自己带来更高收益 \delta/(1+\delta)。因此 \sigma_2^* 是 \sigma_1^* 的最佳响应。然后假设参与人 2 选择 \sigma_2^*。这种情况下如果 z_2 \geq \delta y_2^* 则 \boldsymbol{z} 会被接受,否则会被拒绝。如果是前者则参与人 1 的响应策略对结果没有影响,如果是后者则会得到一个以参与人 2 报价为起始节点的博弈,而此时可以用类似方法证明 \sigma_1^* 是 \sigma_2^* 的最佳响应。
综上所述,我们证明了 (\sigma_1^*, \sigma_2^*) 是子博弈完美均衡。
最后,我们给出两个备注。